.NET and Strings and some interesting tidbits
Strings are one of the simplest yet most abused data structure in most programming languages, including .NET. With the support of String to be a native data type and hence the possibility of it's rampant usage, it makes it even more important for us to understand how they work.
Two important things to be considered as part of the System.String or simply string implementation in .NET are:
1.) Strings are reference types (although they are primitive types)
2.) Strings are immutable -- more about this follows.
Two important things to be considered as part of the System.String or simply string implementation in .NET are:
1.) Strings are reference types (although they are primitive types)
2.) Strings are immutable -- more about this follows.
Without going into details of another .NET programmatic paradigm called AppDomains, let me simply say that they are light-weight processes, just like most can imagine Threads to be, but definitely above that. AppDomains can be thought about the be independent light-weight processes that allow data to be shared across them without the overhead of a process. They have all the independence of a process without any issues like one crashing another and hence provides isolation.
The .NET framework defines and loads it's own standard AppDomains within the execution of the CLR and the other .NET programs. The following image has been reproduced from here.
The .NET framework defines and loads it's own standard AppDomains within the execution of the CLR and the other .NET programs. The following image has been reproduced from here.
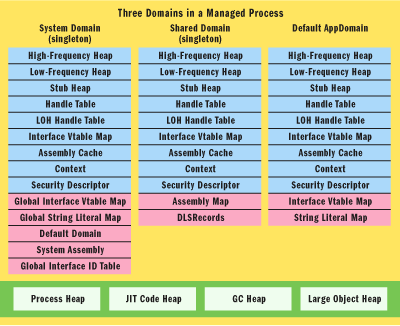
The only thing of interest to us here in this article is the System Domain, and a specific part of that called the "Global String Literal Map". This is nothing but a mapping of all strings that get used within the execution of all .NET programs within the context of a CLR instance. Simply said, the strings across the global space of the CLR is shared and hence avoid their creation multiple times over. To achieve this, they have to be immutable.
The immutability of strings is again something that is new as compared to other programming languages. What this does *not* mean is that string cannot be modified. They can. What this means is that any string, if changed, would create another string whose address would then be different. The previous string will still be stored in the system (provided it is in scope) and not be modified. There references are maintained by the "Global String Literal Map" in the System domain, by the CLR.So, anytime you do a strResult = strVal1 + strVal2, you are creating a new string as expected, but compared to strVal1 = strVal1 + strVal2, you end up creating a new strVal1 while the previous value of strVal1 also remains although not pointed to by strVal1.
Here's another example, which is somewhat analogous.
string str1 = "Some String";
string str2 = "Some String"; //note str1 and str2 are literally the same.
? Object.ReferenceEquals(str1, str2) will return true in the Command window. This means that they are pointing to the same global storage of string data.
This process in .NET-speak is called "Interning".
This specific behavior of string leads to bad programming when used without prior design. String manipulation in .NET is mush faster as opposed to it's prior versions such as Visual Basic, but is still substantial. .NET stores all string representation as Unicode value, which means at least 4 bytes per character to be represented. To avoid all this extra storage would be a good thing to do. This is a tip that you may find all over the 'net, but usage of the StringBuilder class (provided by .NET) for significant amount of string additions is the best thing you can do to get your program to run X times faster, where X depends on how bad a programmer you are. ;)
The System.Text.StringBuilder uses a combination of preallocation of storage and string represented in array format so that repeated addition of string data is stored in subscript values instead of new strings being created. Finally if you need to get the string value back, you can use the ToString() method. The usage of this class is highly recommended, when possible.
---
I did want to write about one interesting aspect of the optimizations performed by the .NET CLR. It highlights how one has to tailor's one's mind specific to the framework of the language under consideration. The usual thought process is that C# is so similar to C, and so any C programmer can easily adapt to C# and be able to write great programs; it does hold true under most cases, but there are always cases when common logic belies observations.
The System.Text.StringBuilder uses a combination of preallocation of storage and string represented in array format so that repeated addition of string data is stored in subscript values instead of new strings being created. Finally if you need to get the string value back, you can use the ToString() method. The usage of this class is highly recommended, when possible.
---
I did want to write about one interesting aspect of the optimizations performed by the .NET CLR. It highlights how one has to tailor's one's mind specific to the framework of the language under consideration. The usual thought process is that C# is so similar to C, and so any C programmer can easily adapt to C# and be able to write great programs; it does hold true under most cases, but there are always cases when common logic belies observations.
Let's us consider two simple loop, placed side by side for comparison:
|
| int[] intArr = new int[10000]; |
Loop 1 requires the length of the array to be checked at every loop iteration to decide whether the go ahead or not, while the other pre-stores the length of the one-dimensional array and uses that to make the decision. Given a decent C background, one is bound to believe that avoiding extra comparisons will make it run faster, hence Loop 2.
Which one do YOU think will run faster in .NET?
The answer is below in white font color, highlight it with your mouse to read it...
In .NET, Loop 1 will run faster. The CLR sees that the comparison factor is the Length property of the array, which can never be an unacceptable value and consequently avoids all checks for the "ArrayIndexOutofBounds" condition. Hence it runs faster.
Enjoy.
posted by Bloomiboy @ 11:58 AM
0 comments
![]()
![]()
